


לקראת רשת משתנים למציאת קשרים בין תוצאות של אלפי מאמרים במדעי החברה - נספח 1
נספח 1 – ניסוי בדיקת היתכנות של בניית רשת משתנים וקשרים סטטיסטיים
על מנת לבדוק היתכנות של המודל ושל הגישה המוצעת לבניית רשת של משתנים סטטיסטיים ביצענו ניסוי פיילוט. במהלך הפיילוט ניתחנו באופן ידני חמישה מאמרים בתחום ניהול מידע אישי (personal information management). ניהול מידע אישי, הוא תחום מחקר העוסק בהתנהגות מידע בה המשתמש מסדר פריטי מידע (כגון קבצים, דוא"ל ומועדפים) כדי לאחזר אותם בעצמו בזמן מאוחר יותר. מידע על חמשת מאמרים אלו מופיע בטבלה 1. כתוצאה מהניתוח חולצו 20 משתנים, 27 ערכים שונים של משתנים אלו ו- 20 מבחנים סטטיסטיים לגבי קשרים ביניהם (מהם 17 קשרי D ו-7 קשרי R). לשם הדגמה נתמקד במאמרים 4 ו- 5. במאמרים 4 ו-5 זוהו שלושה משתנים משותפים: זמן אחזור (retrieval time), שיטת אחזור (retrieval method) ותוצאת אחזור (retrieval outcome). למשתנים אלו היו גם ערכים ספציפיים, כגוןnavigation, search, failure, success . משתנים אלו וערכיהם הופיעו במאמרים בשמות שונים (פירוט בהמשך).
טבלה 1 – פרטי המאמרים בפיילוט.
| Journal | Year | Authors | Paper_name | Paper_id |
| Proceedings of the SIGCHI Conference on Human Factors in Computing Systems | 2014 | Charlotte Massey, Sean Ten Brook, Chaconne Tatum, Steve Whittaker | PIM and personality: what do our personal file systems say about us? | 1 |
| Journal of the Association for Information Science and Technology | 2013 | Ofer Bergman, Noa Gradovitch, Judit Bar-Ilan, Ruth Beyth-Marom | Folder Versus Tag Preference in Personal Information Management | 2 |
| People and computers XVI-memorable yet invisible | 2002 | Mary Czerwinski, Eric Horvitz | An Investigation of Memory for Daily Computing Events | 3 |
| Personal and ubiquitous computing | 2013 | Ofer Bergman, Maskit Tene-Rubinstein, Jonathan Shalom | The use of attention resources in navigation versus search | 4 |
| Journal of the Association for Information Science and Technology | 2010 | Ofer Bergman, Steve Whittaker, Mark Sanderson, Rafi Nachmias, Anand Ramamoorthy | The Effect of Folder Structure on Personal File Navigation | 5 |
מאמר 4 בחן באמצעות ניסוי משתמשים, הבדלים בין השימוש בשיטות האחזור ניווט וחיפוש לצורך הגעה לקבצים במחשב ובפרט בחן את השפעת שיטת האחזור על זמן האחזור ותוצאת (מידת הצלחת) האחזור. מחשב (סוג מכשיר) וקובץ (פורמט המידע המאוחזר) אלו ערכי משתנים שלא נבחנו במאמרים, אך הם מהווים תנאים לקשרים שנבחנו במחקר זה (החלק הימני של תרשים 2).
במאמר 5 המטרה הייתה לבחון את השפעת תוצאות האחזור השונות (כגון, הצלחה וכישלון) על זמן האחזור של קבצים בשיטת הניווט במערכת הקבצים במחשב הנייד. למשל, נמצא בניסוי שנערך במחקר המתואר, כי הצלחה ישירה (direct success) של אחזור הקובץ (ללא טעויות בדרך) לקחה פחות זמן מהצלחה סופית ( eventual success) כאשר המשתמש טעה לפחות פעם אחת בדרך אך לבסוף הצליח לאתר את הקובץ המבוקש) והצלחה סופית לקחה פחות זמן מאחזור שנגמר בכישלון (המשתמש הודיע שאינו מסוגל לאתר את הקובץ כלל). במאמר זה, מחשב, קובץ וניווט הם תנאי המחקר שתחתם נבחנו הקשרים השונים בין המשתנים האחרים (הצד השמאלי של תרשים 2).
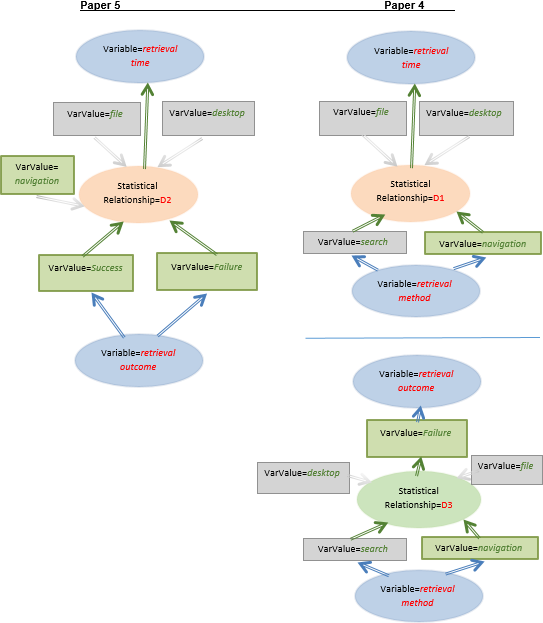
תרשים 2: גרפים של קשרים סטטיסטיים בין משתנים מתוך מאמרים 4, 5. הצמתים (האליפסות הכחולות) בדיאגרמה מייצגות משתנים סטטיסטיים והאליפסות הכתומות מייצגות קשרים סטטיסטיים. המלבנים הירוקים מייצגים את הערכים השונים של המשתנים. החצים הכחולים מייצגים את הקשר בין משתנה לערכיו, החצים הכתומים מייצגים את הקשר בין קשרים הסטטיסטיים למשתנים וערכיהם המקיימים קשר זה ולתוצאות הסטטיסטיות של הקשר. החצים הירוקים מקשרים בין הקשרים הסטטיסטיים לתנאים בהם הם נמדדו במחקרים. באופן עקרוני כל משתנה וערך של משתנה יכול להופיע פעם בתפקיד של משתנה תלוי, פעם בתפקיד של המשתנה הבלתי תלוי ופעם אחרת בתפקיד התנאי לקשר הנמדד בין זוג משתנים.
בשלב הראשון של בניית המודל הרשתי ניתנו שמות סטנדרטיים ייחודיים לכל משתנה וערכיו בשני המאמרים. לאחר מכן כל הופעה של זוג משתנים וקשר סטטיסטי ביניהם נותחה לחוד ונבנה גרף נפרד עבורה כפי שמודגם בתרשים 2. בתרשים זה עדיין לא ניתן לראות את התמונה המלאה והכללית המשתקפת משני המחקרים אלא כל קשר סטטיסטי שנמדד לגופו. בשלב הבא מיזגנו את הגרפים הללו לרשת אחת שבה כל משתנה מופיע פעם אחת בלבד והמידע על הקשרים הסטטיסטיים השונים אשר מגיע ממאמרים שונים משולב יחד לכדי תמונה אחת. תרשים 3 מציג את הרשת הדו-ממדית המציגה תמונה כללית של הקשרים בין המשתנים, ותרשים 4 מציג את הרשת התלת-ממדית המציגה את המידע והמבנה המפורט של הרשת.
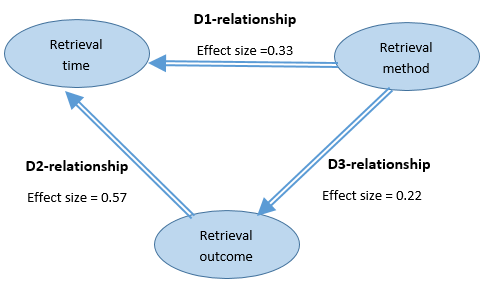
תרשים 3: דיאגרמה מאוחדת דו-ממדית של משתנים וקשרים סטטיסטיים ביניהם מתוך מאמרים 4,5.
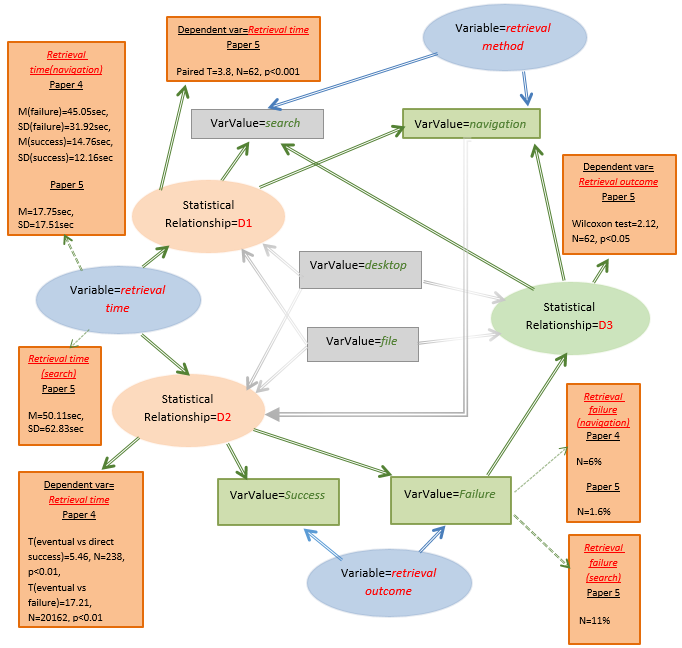
תרשים 4: דיאגרמה מאוחדת תלת-ממדית של משתנים וקשרים סטטיסטיים ביניהם מתוך מאמרים 4,5. הצמתים (האליפסות הכחולות) בדיאגרמה מייצגות משתנים סטטיסטיים והאליפסות הכתומות מייצגות קשרים סטטיסטיים. המלבנים הירוקים מייצגים את הערכים השונים של המשתנים והמלבנים הכתומים מייצגים את התוצאות הסטטיסטיים שהתקבלו במחקרים. החצים הכחולים מייצגים את הקשר בין משתנה לערכיו, החצים הכתומים מייצגים את הקשר בין קשרים הסטטיסטיים למשתנים וערכיהם המקיימים קשר זה ולתוצאות הסטטיסטיות של הקשר. החצים הירוקים מקשרים בין הקשרים הסטטיסטיים לתנאים בהם הם נמדדו במחקרים.
לאחר שבנינו את הרשת המוצגת בתרשים 4 נוכל להשתמש בה לצורך מטא-אנליזה וכריית נתונים באופן הבא. ראשית, מתוך מבנה הרשת נצפה קשר ההשפעה המשולש בין שלושת המשתנים שנחקרו (זמן האחזור מושפע משיטת האחזור ותוצאתו ותוצאת האחזור מושפעת משיטת האחזור), כאשר כל מאמר השלים את ממצאי המאמר השני ותרם קשרים שונים לרשת עבור אותם המשתנים. מתוך הרשת ניתן לראות כי אחוז הכישלונות בניווט נמדד בשני המאמרים והיה נמוך יחסית, וכן ניתן לחשב אחוז כישלונות ממוצע לשני הניסויים שיעמוד על 3.8% (Fitchett & Cockburn, 2015). כמו כן, זמן אחזור בשיטת הניווט דווח גם הוא בשני המאמרים, אולם במאמר 4 נעשתה הבחנה בין זמן אחזור במקרי הצלחה ובין זמן האחזור במקרי כישלון, וכל אחד מן המקרים הללו חושב בנפרד, ואילו במאמר 5 לא נעשתה הבחנה זו. לכן, לשם השוואה בין תוצאות שני המאמרים ניתן לחשב עבור מאמר 4 את זמן האחזור הכללי כממוצע משוקלל כאשר ידוע שמספר הכישלונות עמד על 6% מן האחזורים (45.05*0.06 + 14.76*0.94=16.58) והוא 16.58 שניות בממוצע. תוצאה זו הינה קרובה מאוד לתוצאה שדווחה על עבור משתנים זה במאמר 5 והיא 17.21 שניות בממוצע לסך האחזורים. כלומר התובנה הנגזרת מניתוח הרשת עבור משתנה זה היא כי קיימת התאמה בין תוצאות הניסויים בשני המאמרים. כמובן שמדובר בדוגמא בלבד ולא ניתן לבצע הכללות בעזרת שני מאמרים בלבד, אולם במקרה זה ישנם מחקרים אחרים אשר השתמשו במתודולוגיות מחקר שונות המעידים על תוקף מתכנס ומאוששים את ממצאי המחקרים הללו (Bergman, Beyth-Marom, Nachmias, Gradovitch, & Whittaker, 2008; Fitchett & Cockburn, 2015).
בנוסף על בדיקת ההיתכנות, מחקר הפיילוט לימד אותנו גם על חלק מהקשיים שניתקל בהם בבניית המערכת ועל האופן שבו נעבור מתהליך ידני לשימוש בעיבוד שפה טבעית.
קשיים בהם נתקלנו בפיילוט
אחד הקשיים הבלתי צפויים בהם נתקלנו במהלך הפיילוט היה תנאים סמויים והומוגניים במאמרים מסוימים אשר הופכים להיות הטרוגניים במאמרים אחרים (או הטרוגניים בין מאמרים). לדוגמא במאמרים 4 ו-5 האחזורים נעשו במחשב בלבד ולכן הדבר לא צוין במפורש כתנאי במאמרים. כאשר נתקלנו במאמר המשווה אחזור במחשב לאחזור בטלפון נייד, היה עלינו לחזור למאמרים אלו ולהוסיף "מחשב" כתנאי בדיקה.
בנוסף, כפי שצוין בסקירת הספרות, משתנים שונים וערכיהם הופיעו בשמות שונים. לדוגמא, במאמר 5 הופיע המונח retrieval outcome וכן success rate כמתייחסים לאותו משתנה, ואילו במאמר 4 הופיע המונח percentages of success. במאמר 4 הופיע המונח retrieval method ואילו במאמר 5 הופיע המונח method for accessing files המתייחסים לאותו המשתנה. במאמר 5 המחקר בחן רק את שיטת הניווט (navigation) ולכן מונח זה הוחלף לעיתים קרובות עם המונח retrieval , כגון "navigation success" ו-"retrieval success" כבעלי אותה המשמעות. בעיה זו נפתרה כאמור בעזרת סטנדרטיזציה של שמות המשתנים. המערכת שבנינו לא מאפשרת להכניס נתונים לגבי משתנים טרם הוגדרו וקיבלו שם סטנדרטי.
המעבר מעבודה ידנית לשימוש בעיבוד שפה טבעית
על מנת לבחון כיצד יהיה ניתן לזהות את משתני המחקר והקשרים הסטטיסטיים ביניהם בצורה אוטומטית, זיהינו תבניות המכילות מלות מפתח אופייניות (כגון, t-test, test, t, r, p, Pearson) שחוזרות על עצמן במאמרים, כגון, במשפטים (שמות המשתנים והקשרים מודגשים ורכיבים שחוזרים על עצמם צבועים בירוק):
“We found that the number of words recalled after navigation was larger than the number of words recalled after search (t(26)=2.39, p<0.05)”
“As we expected, retrieval time for Direct Success navigations was shorter than for Eventual Success navigations (t(1,060)=17.21,p<0.01)”.
“The question was tested by comparing retrieval time, number of mistakes and percentage of failed retrievals”.
“Comparison of retrieval time and number of mistakes used a paired t-test…”
"We tested the relations between folder size and retrieval outcome using t-test..."
עבור משפטים לעיל ניתן להגדיר את שתי התבניות הבאות שמאפיינות אותן:
<[any word/s] [dependent variable name] [preposition] [independent variable value] [is/was] [adjective] than [independent variable value] [test name]=[result]>
<[comparison/comparing/relation] [preposition] [variable value name] [and] [variable value name] [use/using/used] [test name]>
לאחר זיהוי שמות המשתנים מתוך התבניות הבסיסיות ניתן לחפש את הופעותיהם של שמות אלו בטקסט ובכך לזהות תבניות נוספות. באמצעות תבניות חדשות ניתן לשלוף משתנים נוספים. תהליך זה יכול לחזור על עצמו מספר פעמים עד שלא ניתן למצוא משתנים חדשים.
תאריך עדכון אחרון : 05/03/2019
